
Introduction
Le volume de données générées annuellement a littéralement explosé au cours de ces dernières années. En 2012, on se targuait de produire autant d’informations en 2 jours qu’en deux millions d’années, d’être passé de la disquette 5 pouces ¼ à des unités de stockages ayant dépassé le Teraoctet. Que devrait-on dire alors aujourd’hui ? Et quels superlatifs utilisera-t-on demain ?
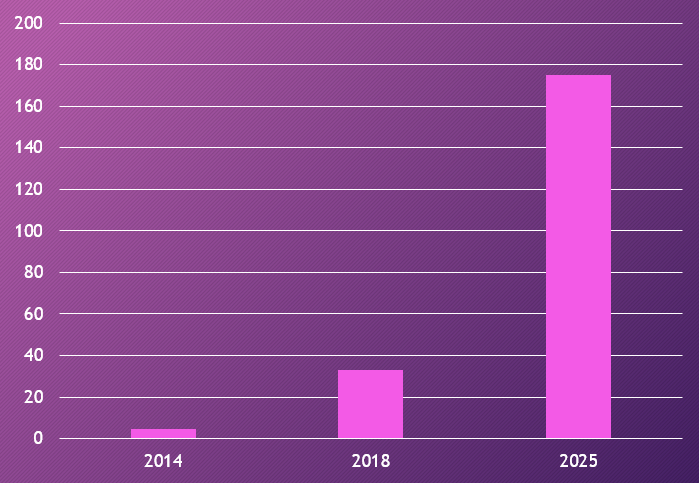
Comme le montre le graphique ci-dessus, l’accélération ne fait que commencer :
- 4.4 milliards de To / an en 2014 (source IDC)
- 33 milliards de To / an en 2018 (source IDC)
- Prévision de 175 milliards de To / an en 2025 (source IDC)
Les raisons de cette explosion ?
- Les réseaux sociaux
- 4,2 milliards d’internautes (55% de la population mondiale) – 2018
- 3,4 milliards d’utilisateurs des réseaux sociaux (44%) – 2018
- 3,2 milliards d’utilisateurs des réseaux sociaux sur mobile (42%) – 2018
- Le cloud
- 70% des entreprises investissent dans le cloud (2018, source KPMG)
Les différents type de données
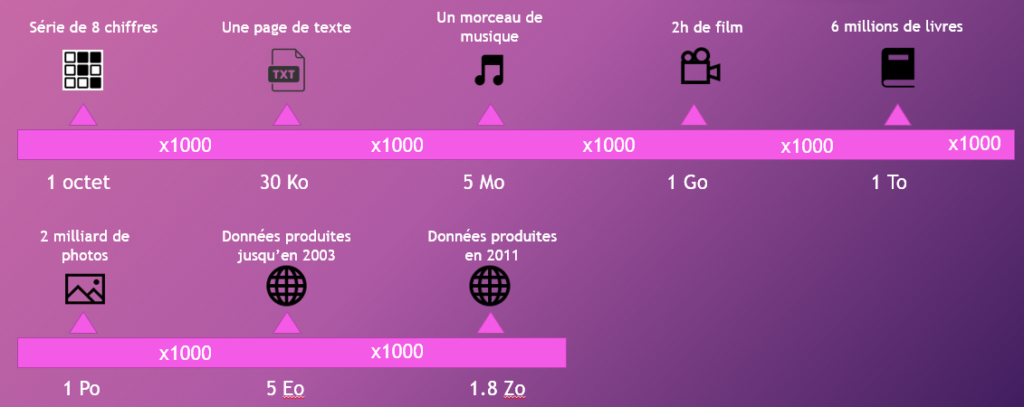
Il est difficile de se représenter le volume de données stocké dans 4.4 milliards de teraoctets.
L’image ci-dessous donne une petite idée de l’information stockée en fonction des différentes unités de mesure utilisées pour représenter les volumes de données (de l’octet au zetaoctet).
Les données sont catégorisées en 3 types :
- Les données structurées : la structure de ces données est fixe, la liste des propriétés qui la compose est une liste finie. Ces données sont stockées dans des bases de données relationnelles comme SQL Server, mySQL, Oracle, …
- Les données semi-structurées : elles ne répondent pas aux critères des données structurées mais possèdent néanmoins des marqueurs ou balises permettant de hiérarchiser la donnée. Elles sont souvent stockées dans des fichiers xml ou json.
- Les données non-structurées : elles ne possèdent aucun modèle prédéfini et ne sont pas organisées de manière prédéfinie. Exemple : logs, images, vidéos, …
Quelques problèmes liés à l’explosion des données
On estime qu’environ 70 à 80% des données sont non structurées ce qui pose un problème pour leur exploitation.
En effet, les outils traditionnels, issus du traitement des données structurées ou semi-structurées, ne sont pas adaptés pour requêter ce type de données ou pour les synthétiser.
D’autre part, la question de la pertinence se pose. Compte tenu des milliards de teraoctets générés, quelles sont les données réellement utiles ? Et si elles ne sont pas utiles (ou utilisables) aujourd’hui, est-ce qu’elles ne le seront pas demain ?
Le terme de Dark data a fait son apparition il y a quelques années pour qualifier ces données générées par les entreprises mais non exploitées.
Caractéristiques des problèmes liés au Big Data
Le propre d’un projet Big Data c’est d’être confronté aux 3V :
- Volume : les données représentent plusieurs To ou Po et continuent de croître ;
- Variété : pas uniquement des données structurées, mais la collecte contient également des données semi-structurées ou non structurées ;
- Vélocité : besoin d’immédiateté pour recevoir ou traiter les données.
Certains spécialistes parlent même de 5V :
- Véracité : les données étant destinées à prendre des décisions ou à faire de la prédiction, il est préférable de contrôler que les données collectées sont correctes ;
- Visibilité : besoin de restituer l’information et de l’afficher aux utilisateurs.
Afin de rendre un peu plus concrets ces concepts, voici ci-dessous quelques exemples de projets Big Data :
- Santé – Anticipation des épidémies
- Immobilier – Approcher les vendeurs de bien avant les concurrents
- Banque/Assurance – Détection des fraudes
- Opérateur Internet – Prévenir les pannes sur les « box »
L’approche classique qui consiste à définir des besoins, à modéliser une structure de données et à itérer sur les demandes d’évolution ne convient pas à un projet Big Data. L’approche est orientée « données » :
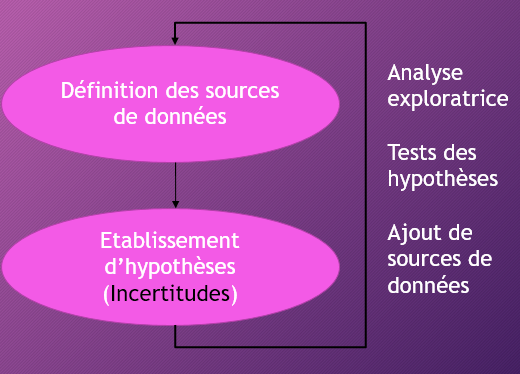
A partir d’un objectif (ex : anticiper les épidémies), on définit les sources de données qui pourront nous aider à répondre au besoin (ex : déclaration des médecins, ventes en pharmacie, météo, …) et nous établissons des hypothèses sur ces sources de données pour établir une prédiction. Si les prédictions sont insatisfaisantes, les sources de données pourront être enrichies et leur prépondérance dans la prédiction sera affinée.
Les outils du Big Data
Pour répondre aux contraintes, de nouveaux outils ont donc vu le jour au cours de ces 15 dernières années.
La frise chronologique ci-dessous présente les grandes étapes de l’outillage depuis les années 2000.

MapReduce (développé par les équipes de Google) a été l’un des premiers outils élaborés pour répondre aux contraintes de volume et de traitement distribué. Il repose sur le principe du « Diviser pour mieux régner » afin de déléguer de petites tâches à un ensemble de serveurs.
Ci-dessous un exemple de traitement distribué avec MapReduce pour compter le nombre de lettres dans un texte.
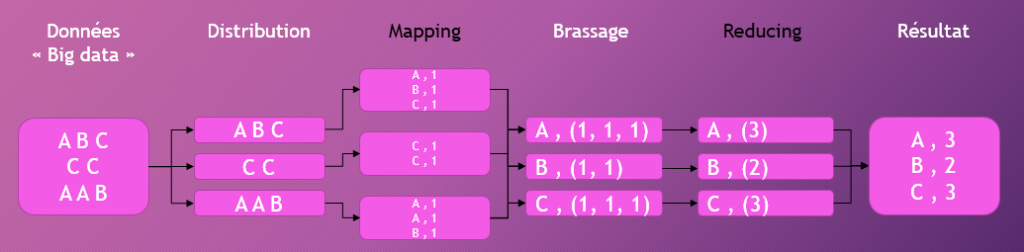
- Etape 1 : Distribution des textes à 3 nœuds (serveurs), 1 ligne par nœud ;
- Etape 2 : Traitement de la donnée sur chaque nœud, chaque serveur compte le nombre de lettres de sa ligne (Map) ;
- Etape 3 : Consolidation de la donnée, chaque nœud se charge de regrouper une lettre ;
- Etape 4 : Réduction (Reduce), chaque nœud compte le nombre d’occurrences de la lettre dont il avait la charge ;
- Etape 5 : Consolidation du résultat.
Dans l’écosystème des outils Big Data on trouve, entre autres :
- Les outils du
framework Hadoop
- MapReduce / Spark : Calcul distribué
- HBase : base de données distribuée
- Hive / Pig : Outils d’analyse de données
- ZooKeeper : Outil de configuration des architectures distribuées
- Base de
données
- Cassendra
- MongoDB
- MemSQL
- Traitement de
la donnée
- OpenRefine : Nettoyage des données
- RapidMiner : Analyse / Manipulation des données non structurées
- ElasticSearch : Moteur d’indexation et de recherche des données
Les métiers du Big Data
Le Big Data a également fait naître de nouveaux métiers au-delà des traditionnels développeurs, architectes et administrateurs bien connus dans le domaine de l’informatique.
- Data Engineer : En charge de la gestion de la donnée, il collecte et traite les données.
- Data Scientist : Il s’occupe de l’analyse de données, il extrait les informations utiles de la masse.
- Growth Hacker : Il met en place des techniques marketing pour augmenter la masse de données collectées.
- Data Protection Officer : Il garantit la protection des données personnelles.
Du Big Data à l’IA (Intelligence Artificielle)
Le Big Data a été un véritable accélérateur pour le développement de l’intelligence artificielle. La qualité des prédictions et de l’apprentissage s’améliore grandement avec la quantité de données. L’IA a besoin de s’alimenter de données pour affiner le poids des paramètres pour obtenir la prédiction la plus fiable.
L’exemple ci-dessous présente des données structurées pour identifier si un animal est une vache ou un taureau à partir de paramètres prédéfinis (nombre de pattes, présence d’une moustache, taille, poids) :
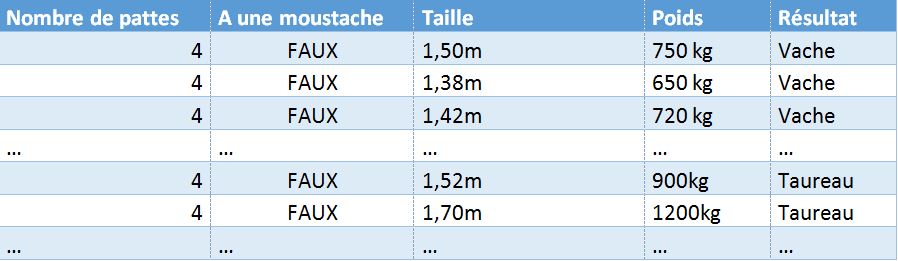
L’IA va très vite identifier que les deux premiers paramètres (nombre de pattes, présence d’une moustache) ne sont pas discriminants pour obtenir le résultat. En revanche, la taille et le poids permettent de réaliser une prédiction avec un pourcentage de certitude assez élevé, si l’IA a observé un nombre suffisamment important de vaches et de taureaux.
L’IA repose aujourd’hui essentiellement sur deux méthodes d’apprentissage :
- Machine Learning : basée sur un apprentissage statistique (comme dans l’exemple ci-dessus), cette méthode renvoie des résultats de type numérique, classification ou score.
- Deep Learning : basée sur les réseaux neuronaux pour rechercher des modèles ou des corrélations, cette méthode renvoie des résultats plus variés : langage naturel, image, …
Conclusion
Nous ne sommes qu’aux prémices du Big Data, les projections sur les volumes de données à venir sont sans commune mesure avec ce que nous connaissons aujourd’hui. Mais d’ores et déjà, les volumes actuels nous ont confronté à des problèmes pour lesquels des outils et de nouvelles méthodes ont été créés.
L’accélération du Big Data s’apparente à l’avènement de l’IA, les données collectées peuvent être utilisées pour alimenter des réseaux neuronaux en charge de modéliser les données et d’établir des prédictions.