
Le 25 janvier, afin de clôturer la trilogie, Stéphane nous a parlé plus précisément de l’automatisation continue ou du CI/CD.
Pour rappel, voici le travail que nous avons poursuivi jusqu’à présent lors du 1er et du 2ème Wiki Déj dédiés au DevOps :
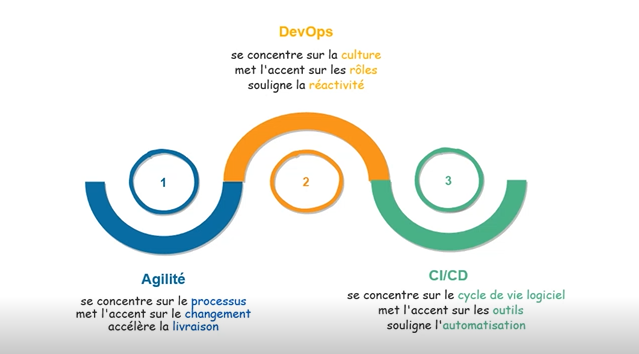
L’automatisation du cycle de vie logiciel
La finalité du CI/CD est d’automatiser
- En garantissant la qualité et la sécurité
- En passant moins de temps sur les tâches répétitives (tests, …)
- En mettant plus rapidement dans la main du client
- En se libérant du temps pour plus de valeurs (travailler quelque chose de nouveau, …).
Dans l’environnement DevOps, on parle de CI (Conitnuous Integration) et CD (Continuous Delivery/Deployment).
Continuous Integration
- Construire une version (images, packages, dépendances, …). On construit un logiciel avec différents types de langages, on compile et on build le logiciel pour obtenir un .exe (fichier exécutable). Il nous permet de réaliser ce que l’on demande au logiciel.
- Tester (couverture de code, unitaires, non-régression, …). Les tests sont de différentes natures en fonction de l’avancement et de ce que l’on vient de réaliser.
- Sécuriser (analyse des failles, …). On fournit un livrable avec des dépendances qui sont à jour et sans failles, et on le vérifie.
Dans le cas de bugs en livraisons à la fraîche (comme l’exemple d’actualité de ce début d’année), il faut savoir dans quelle version l’on est, upgrader et livrer rapidement. Les personnes ayant mis des chaînes CI/CD peuvent livrer beaucoup plus rapidement la correction du bug puisqu’ils ont tous les éléments et les moyens pour mettre en production.
Continuous Delivery / Deployment
Le delivery correspond à la livraison. On peut le voir également en fonction des différents rôles dans l’équipe : les développeurs livrent et l’exploitant implémente / déploie.
On peut réaliser la livraison en manuel et le déploiement en automatisé, ou alors tout peut être automatisé.
- Construire / adapter l’environnement à la demande. Il s’agit de l’infrastructure, la plateforme finale. Il est possible avec une nouvelle fonctionnalité de mettre un nouveau composant (services ou micro-services comme nouvelle base de données, serveur web, update, …).
- Observer le fonctionnement (intégration jusqu’à la production). On a besoin d’un tableau de bord pour savoir si l’on reste dans les « bons régimes » : est-ce que l’on ne va pas trop vite ? Ou pas assez vite ?
Cela nous permet d’avoir des indicateurs de conformité par rapport à ce qui était prévu. Il s’agit du monitoring.
- Être réactif sur les incidents. Un incident signifie un impact utilisateurs donc un client mécontent. Plus on est proactif et l’on anticipe, plus on pourra corriger.
Ce sont des étapes que l’on connait et maîtrise bien manuellement sur les projets : il s’agit ici en DevOps de les automatiser et de packager l’ensemble.
Comment mettre en œuvre ?
On réalise une « pipeline » : c’est une série d’étapes qui permet de construire le logiciel, puis de le tester, puis de vérifier la sécurité, puis de l’intégrer, puis de le déployer en production…
L’outillage utilisé est primordial : Gitlab CI, GitHub Actions, Jenkins, Circle CI, Tekton… Ces logiciels permettent de faciliter cette automatisation.
A savoir que la pipeline est écrite comme du code. Il y a une syntaxe à respecter en fonction des outils (malheureusement, ce langage n’est pas standardisé).
Elle se décompose par étapes qui contiennent elles-mêmes des jobs (qui font les tâches manuelles en les reproduisant soit au-travers de scripts ou alors de lignes de commande spécifiques).
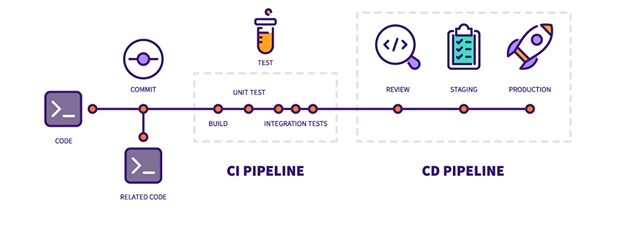
Dans la partie gauche, on retrouve le code et les dépendances qui y sont liées. Il y a également le « commit » : c’est la validation qui déclenche les étapes suivantes. Je fais une sauvegarde et je déclenche la partie pipeline avec le CI dans un premier temps.
Dans la phase « intégration de tests », souvent avec un système bouchonné ou de simulation, on vérifie que l’API est bien appelée et qu’elle répond également toujours la même chose.
Dans la partie CD, on va potentiellement faire des revues de code ou des analyses complémentaires, ou encore des mises en situation pour des tests complémentaires sur d’autres plateformes.
Le « staging » représente la plateforme d’intégration : la plateforme et l’infrastructure sur lesquelles tournent le logiciel qui interagissent avec un écosystème externe. Par exemple, un site web qui récupère la météo depuis un autre site web. Cela se fait souvent au-travers d’API et le logiciel peut ainsi récupérer les informations. Contrairement à l’environnement CI, on interroge une autre plateforme qui nous apporte plus de réalités et un jeu de données beaucoup plus large. On valide en même temps la capacité à utiliser le réseau.
Le « staging » permet de simuler un environnement plus proche de l’opérationnel.
Si chaque étape se déroule bien, la pipeline se déroule jusqu’au bout : la production.
Cas pratique
Pour mieux illustrer ses propos sur la pipeline, Stéphane nous en a réalisé une simple grâce à sa présentation hébergée sous Gitlab :
On prend des fichiers sources au format markdown (décrit du texte en code comme Wikipédia par exemple) que l’on transforme grâce au CI/CD en pages HTML nous permettant de créer un site web.
Voici le code projet :
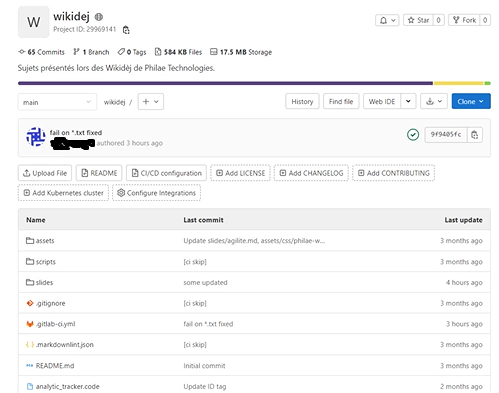
Ici, seulement du texte est formaté mais cela pourrait être du Java, du Python ou autre.
On y retrouve un environnement complet avec le plus important : le fichier gitlab-ci.yml qui est la pipeline décrite.
On peut éditer les fichiers et ainsi dérouler les étapes de la pipeline qui se décrivent sur la droite en instantané :
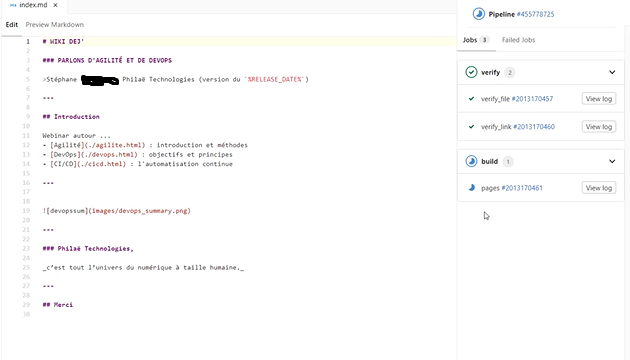
Voici un exemple de la pipeline lorsque des erreurs apparaissent :
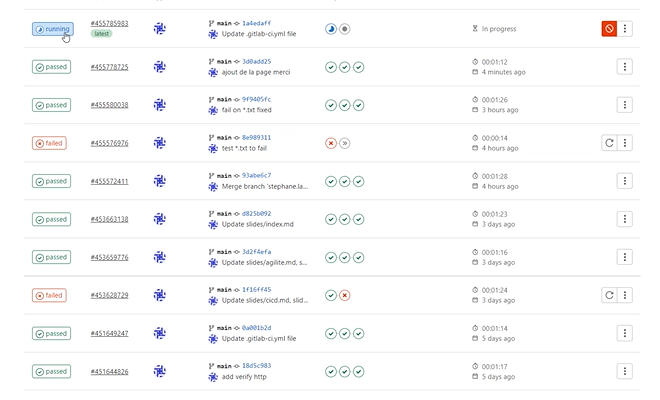
Dans le détail, ça donne :
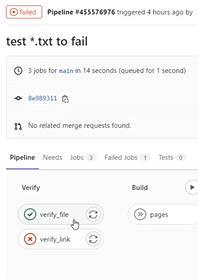
L’erreur bloque le reste de la pipeline. On s’arrête et on corrige.
Ici, vous pouvez voir les étapes déroulées lorsque tout se passe bien :
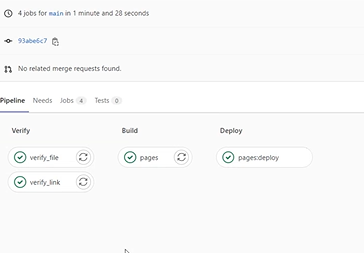
Comme je ne le fais pas manuellement, je reçois des rapports me disant si cela c’est bien ou mal passé. Pendant ce temps, je peux travailler sur autre chose apportant de la valeur ajoutée.
A retenir
Le CI/CD :
- Se concentre sur le cycle de vie logiciel
- Met l’accent sur les outils
- Souligne l’automatisation.
Les métiers évoluent avec le DevOps et une notion émerge : la SRE (Site Reliability Engineering). C’est une fonction assurant la qualité de vie logiciel (opérationnelle) / des sites web.
Dans le monde anglosaxon (notamment chez Google), ce nouveau métier arrive très fort.
Pour poursuivre encore un peu, nous vous donnons rendez-vous dans le prochain article résumant les échanges qui ont suivi la présentation. 😀